Traning Text Classifier
Because our goal is solely to categorize the text, we can utilize only the encoder-based model, as we don’t need to generate different text outputs, which would require a decoder.
Let’s look at the encoder-based model.
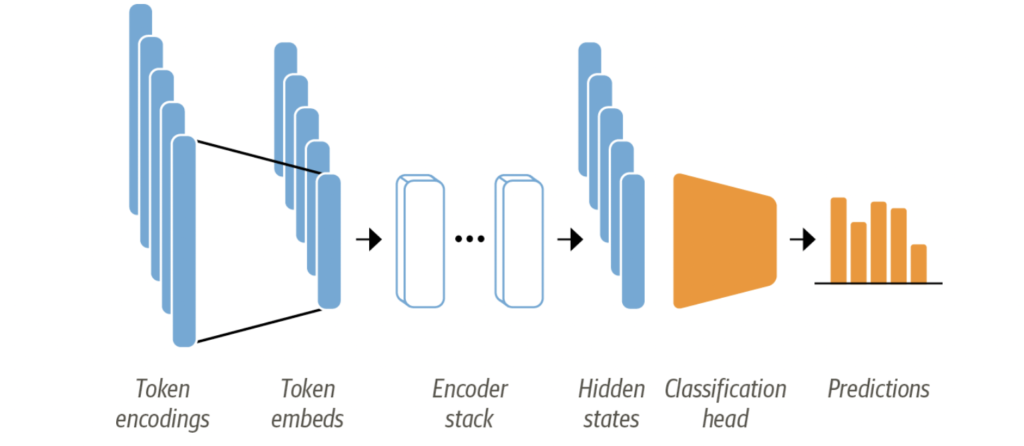
The texts are converted to embeddings before feeding them to encoder stack which will output a hidden state for each of the tokens. We can take use of hidden states to train our classifier in 2 ways:
- Transformer as Feature Extraction: In this model, we train our classifier without modifying parameters of pre-trained model
- Transformer as Fine-Tuning: In this model, we train our classifier while modifying parameters of pre-trained model
No comments yet! You be the first to comment.