Transformer as Feature Extractor
Utilizing a transformer for feature extraction is a straightforward process. In this method, we keep the core weights of the transformer unchanged (frozen) during training and employ the hidden states as the input features for our classifier. The primary benefit of this technique is the ability to efficiently train a simpler or less complex model. This model could be a neural network layer designed for classification, or it could be a non-gradient-based approach like a random forest. This approach is particularly useful when GPUs are not accessible, as it requires the hidden states to be calculated just once beforehand.
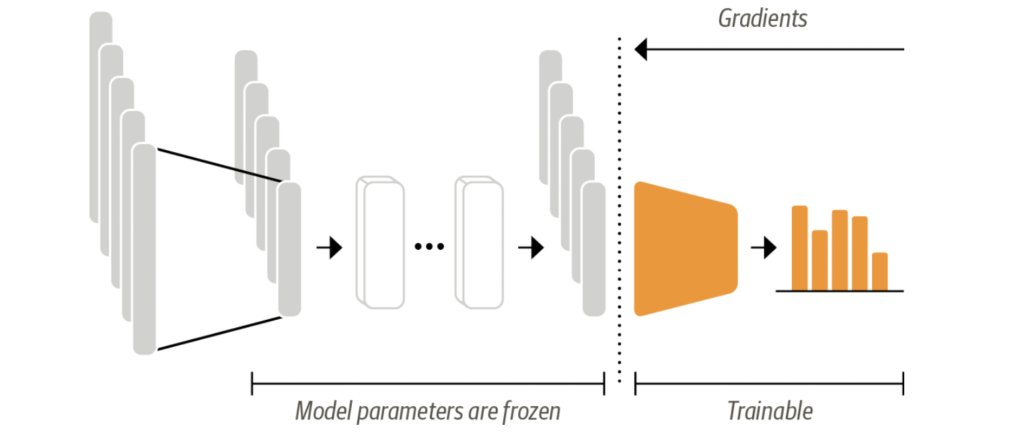
We can take advantage of Hugging Face pre-trained model for computing the hidden states of token
from transformers import AutoModel
model_ckpt = "distilbert-base-uncased"
model = AutoModel.from_pretrained(model_ckpt)AutoModel is a class from the Hugging Face Transformers library, a popular and widely-used library in the field of natural language processing (NLP). The AutoModel class serves as a generic interface that abstracts away the need to work with model-specific classes directly.
Next step would be to generate token embeddings for the input text, which we have already seen in previous tutorial
text = "this is a test"
inputs = tokenizer(text, return_tensors="pt")Now the final step in process of extracting the hidden states is to feed the token embeddings to the model we have used above
inputs = {k:v.to(device) for k,v in inputs.items()}
outputs = model(**inputs)Here outputs is an instance of BaseModelOutput class , we can extract the last hidden state from the outputs using its “last_hidden_state” attribute
last_hidden_state = outputs.last_hidden_stateWe have Preprocessed our dataset for training our text classifier, Lets now create a feature matrix where we use hidden states as input and out labels as output
import numpy as np
X_train = np.array(emotions_hidden["train"]["hidden_state"])
X_valid = np.array(emotions_hidden["validation"]["hidden_state"])
y_train = np.array(emotions_hidden["train"]["label"])
y_valid = np.array(emotions_hidden["validation"]["label"])To train a classifier, we can use any classifier algorithm but for the sake of this course we are using LogisticRegression
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter=3000)
lr_clf.fit(X_train, y_train)